Three years ago I noticed some drastic changes to YouTube which I and many others didn’t like. For example the removal of the dislike count, or the automatic removal of comments, or the like / dislike numbers being magically altered. There was a real fear YouTube would eventually remove community comments, and video comments all together.
But it really all started many years ago when someone at YouTube decided to stop showing new videos of channels you subscribed to. Imagine that, a channel I like, and YouTube won’t show it to me on the homepage? And then they took control the trending section, remember the massive Alex Jones and Joe Rogan podcast years ago? Millions of views in a few days, not a peep on the Trending section.
Topics I’m interested in are pushed to the side, and whatever mindless advertiser-friendly video is pushed to the front. And I don’t have any control over it. I feel like we’re entering Idiocracy territory.
 Watch mindless videos for days
Watch mindless videos for days
I personally don’t care if it doesn’t fit my political / whatever viewpoint. If it’s a quality video I want to see it. I feel like we’re in this massive psy-op, if a YouTuber doesn’t toe the line, they’re out. No longer recommended, can no longer be mentioned and blacklisted – persona non grata.
Not only that, YouTube can decide it doesn’t like a certain type of topic and ban it over night. Anyone remember ASMR? It’s been nuked.
A few months ago I started seeing certain videos beeping out sensitive words, like drugs, murder, etc. Because there was a theory this would hurt the visibility of your video. YouTube is turning into…. television. It’s now CorpTube. It’s been known for years certain late night shows and traditional media get a boost on the recommendation algorithm. They can even mention certain topics but you cannot.
The last nail in the coffin was the search functionality. It’s now a mere suggestion to the algorithm, you get 5 crap results back from their approved list of channels and then you’re seamlessly put back on to the treadmill of mindless videos.
And Google also owns YouTube, which is, according to this investigative journalist, the worst social media company (it’s also ironically hosted on YouTube).
The You in YouTube
I want the old YouTube back. The place where you go to explore and find creative videos on topics you never would have thought of. People making videos, not for the money or the algorithm, but for the enjoyment, expressing themselves, it was always an adventure. One thing I always enjoyed was animation but it’s all dead on YouTube. The algorithm wants constant videos to feed the machine. Animation is just too time intensive.
There are some creators that gave up, they don’t want to constantly pump out videos. There is one creator Joel Haver, which doesn’t care about the algorithm and is doing what he enjoys. Making full length movies. I respect that, we need more creatives like this.
When was the last time you watched a full-length movie on YouTube? Ok… When was the last time the algorithm was recommended it to you? Never.
A few months ago I was re-reading one of my favorite books, Lincoln Unknown by Dale Caregnie. He originally wrote it because there wasn’t any complete material going in depth into his life. So he spend years researching and published it. Can you imagine a YouTuber putting in this much effort into one video? Don’t get me wrong, they are not lazy, it just doesn’t make sense due to the fast-paced nature of algorithm. Although the closest channel I can think of would be The Why Files.
There are plenty of high-quality videos which the algorithm just doesn’t like. How can we take back control and find things we want to watch?
The Old Internet
A few days ago, I was searching for some information on a game from 20 years ago. I stumbled upon a relic from the past, a forum post from 2004! One thing that shocked me was the amount of outbound links, each person could freely post links to their site, or whatever in their signature. But the most shocking part was that the post was a series of links to this persons personal blog. All the answers were there but I had to go to their site to find it.
Can you imagine that happening today? All social media sites and even the users hate going off the “platform”. The content needs to be in the post or a mod will take it down. Social media sites, like Facebook, hate when you post external links. On Reddit you can’t even post a link to some sites like Bitchute or Rumble. So much for “surfing” the internet.
By the way for searching the old internet, I would suggest trying marginalia.
Breaking the Kingdoms

The internet has turned into divided social media kingdoms. Personal sites, forums, are no longer needed. You must be in these kingdoms to connect to people, and once inside they don’t let you get people out of them.
Last year there have been some progress. For example Lemmy and the fediverse has grown in popularity but they have their own issues. For example the difficulty of running a lemmy instance or the devs refusing to add features needed by the lemmy server managers. It’s also actively under attack by the bigger guys.
I wanted to do something about it but something I thought was possible for one person. And that was solve the video searching problem. Since YouTube, there have been many more video platforms but they all seem to be unsearchable. Take for example Google:
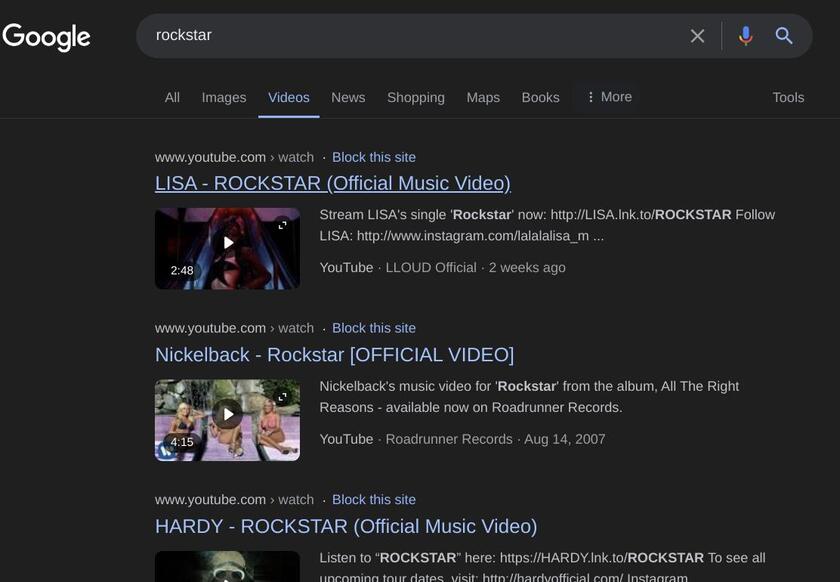 Google only showing YouTube videos
Google only showing YouTube videos
Google only shows YouTube videos, but what about Rumble? Newgrounds? Vimeo? PeerTube videos? For PeerTube videos you’ll have to use Sepia Search, which most people won’t bother.
So why don’t I create a crawler, gather up all these videos and put them on a simple search service. Going into this task, I thought the biggest hurdle would be not getting ip banned. It turns out, only YouTube banned me for 24 hours because of a raw curl call (I was testing something). After that it was all smooth sailing.
For anyone doing this I recommend registering your crawler here.
I didn’t start with an empty database, I used this youtube video id list and thisas a seed.
 The homepage
The homepage
I did some math and figured 2tb of storage could fit all 2 billion videos, but I didn’t know YouTube alone has over 14 billion! And it adds thousands every second. How can my crawler keep up? Well as you’ll find out, it can’t.
This is one major hurdle, YouTube prioritizes recent videos. Anything over a year old, you basically will almost never be recommended. This is the new social media. It needs to be current. Which is why YouTube creators always push out constant new videos, even if they already covered the topic.
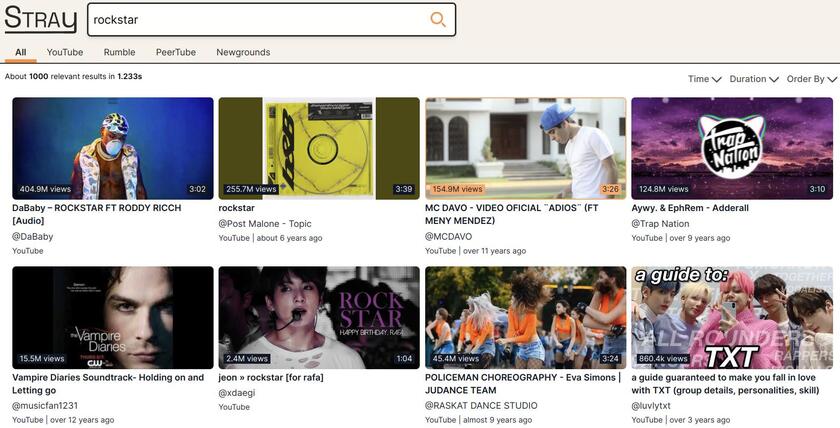 Search results
Search results
After about a month of work I got crawlers working for most platforms. The crawlers use a combination of html parsing and json apis. I would estimate my crawlers gather about 1 million videos a day. This was mostly due to using the bloom filter, this is a quick way to filter out things alread y seen before.
The crawlers would always start on the websites homepage or trending feed. From there it will look for new videos, channels and then follow the video recommendations. Pulling any useful data like like count, view count, description, title, etc. This would later be used to rank the videos quality. Because of so many videos being found and not enough time to pull them all (The crawler only hits a page once every second), a RequestQueue table was created to hold the next page to hit.
My stack was as follows:
I also created Keyphrase to retrieve useful terms from video titles.
Search Indexing
After seeding the database with 1.4 billion videos, and 85 million channels. I realized what working at “scale” means. Any schema migration takes minutes not seconds, and indexes now matter a lot. Now every migration needs careful consideration and planning. This isn’t ideal because moving fast helps iterate quicker, but that was the least of my problems.
Indexing this data so users can query it was a massive challenge, because videos were coming in by about a million a day. I needed something really fast at indexing and won’t need too many server resources. Most people would go with the standard Elastic Search, but from my calculations it would take 4 beefy servers to handle this load, cause Java? I needed something more lean, so I looked at the latest tech.
On top of that, db optimzations were important. Here are some resources around that:
- Glove
- Optimizing full text search with postgres
- Lessons learned scaling postgres
- How to build a search engine with rails
- Postgres performance tuning
- Fasttext
- pgtune
- Format of YouTube ids
- Search Quality Algorithms
- Transducers
ParadeDB
By luck has it, I found this new product which promises to leverage your existing postgresql db to do fast queries. Batteries included etc. The db was brought to it’s knees after a million records. But I could see this working for anything less than that.
Meilisearch
Next up was Meilisearch, on paper it looks great but after reading this review. I wasn’t convinced this would work.
This one failed horribly, it could barely index 1000 records a second and cpu usage was very high. Didn’t fit my use case.
Sonic
After some digging, Sonic seemed to be a good option. Lightweight, built in Rust and can handle millions of records. At this point I just wanted something that could get any results.
This kinda worked, but it has some major limitations:
- No filtering.
- No sorting.
- Only returns ids of records.
- Requires language of text.
- A lot of hash collisions because it’s xxhash algorithm only uses 32 bits!
After some performance testing, it could index something like 5,000 videos a second – to be honest I don’t remember. But after 100,000 inserts, the server would just hang. I suspected there was some race condition which caused the write lock to never unlock. So I had to slow down inserts even more.
But the killer was the hash collisions. When text is sent in it gets chopped up into tokens and each token is hashed to a 32bit integer. This saves a lot of space and speeds up searching, but has the potential problem of two different strings converting the same number. This would mean two totally unrelated videos would appear in your search results. More info here.
Language Detection
Sonic requires – or would like – the language of the given text so it can tokenize better. At this point the crawler would index everything, so there were many videos in different languages. In the end I had to implement a method of language detection.
They use Whichlang on the backend:
My Own Implementation
After discussing this problem with the wider community – mostly the dev from Marginalia. He mentioned he created his own search engine to index web pages. I figured, there was nothing on the market and hey it’s a good excuse to use Crystal.
So I essentially took the Sonic implementation, rewrote it in Crystal and then added some necessary features like filtering. You can view the code here.
This should have been the end of this journey but it wasn’t. The major issue is tokens are in 32bits and should have been 64bits. After indexing millions of records, you’ll get a lot of hash collisions. And also performance, after implementing filtering search queries slowed down. This got me down the rabbit hole of Roaring Bitmaps, and more info.
At this point, the complexity is just too high. I can’t spend all my time building a search engine, so back to searching for an alternative.
Lnx
Using Tantivy as the backend, Lnx offers an easy to use API for indexing anything. It’s kind of a pet project but I gave it a test anyway. I ended up using their Open API json to generate a ruby client.
The results were amazing. Over 10,000 ingestions a second! This was it. But the Lnx API had it’s own limitations. If moving forward, I needed full control over the API, so I started a Tantivy Crystal binding library. It was never finished but maybe it can be used by the community to learn from.
Future of the Project
At this point it was about 3-4 months into this project and came to the realization of a few things.
Getting Good Results is Hard
Millions of videos are online and how do you judge which one is worth watching? The original search algorithm took a combination of like count, view count, etc to boost the visibility. But YouTube videos would always have the most views for obvious reasons. On top of that videos don’t provide enough important information to judge the content. Videos posted many years ago had simple titles and maybe more info in the description but creators today know YouTube ignores the description content so all the keywords are pushed into the title. This has made the description really a place to dump links for marketing and referrals.
YouTube in it’s search ranking algorithm will also take into account the channels popularity. But this was something I didn’t explore.
Do you know how many results I got when searching for Pokemon? Hundreds of thousands, short videos, long videos etc. The best solution is to sort by most views, you’ll end up getting something decent, but then there is the time issue. Users generally don’t want to see popular videos from 2 or 5 years ago, that’s old news on the internet.
Maintaining the Crawlers
I’ve seen every internet protocol error, and parsing error imaginable at this point. I ended up creating a Telegram Notifier for the Exception Notification gem to log all these errors and easily view them on my phone.
Besides the common timeout error or connection lost error, parsing errors were quite common. Parsing a sites homepage for new videos and channels is sensitive to any html changes. I looked into using AI to generate the parsing code, so the crawler can handle html changes but I never got around to this. Just recently BitChute redesigned their site and I don’t have the energy to update the crawler.
Here is a snippet of the RumbleCrawler. It uses some tricks to avoid selecting specific element names, because I found they can change sometimes. Instead I took a generic root element and regex it’s text for the data.
def get_extra_info response
# Find the element with the like count
like_count_element = response.at(".main-content").text.match /([0-9\.]+[km]?)\n /i
# Extract the like count
like_count = dehumanize like_count_element[1]
body = response.at(".body-container")&.text
body = response.at(".media-page-chat-body-container").text if body.nil?
# Find the element with the total views
total_views_element = body.match /\t([0-9\.]+[kKmM]?)\t/
# Extract the total views
total_views = dehumanize total_views_element[1]
comment_text = body.match /Loading ([0-9\.]+[km]?) /i
if comment_text.present?
comment_count = dehumanize comment_text[1]
else
comment_count = 0
end
keywords = response.css(".video-category-tag").map do |v|
v.text.strip.gsub(/\#/, "")
end
data = {}
data[:like_count] = like_count if like_count.present?
data[:view_count] = total_views if total_views.present?
data[:comment_count] = comment_count if comment_count.present?
data[:keywords] = keywords
data
end
And then this raw data is put through a dehumaize process. Meaning it’ll take text like 10:00, or 10.1k views, or 10 minutes and turn it into the appropriate number. Here is the code for that:
def dehumanize(value)
return value if value.is_a?(Numeric)
return 0 if value.nil?
value.try :strip!
if value.match /\d+,\d+/
return value.delete(',').to_i
end
duration_parts = value.scan(/\d+/) # Extract numerical parts
if duration_parts.count == 3
hours = duration_parts[0].to_i
minutes = duration_parts[1].to_i
seconds = duration_parts[2].to_i
# Calculate the total duration in seconds
return hours * 3600 + minutes * 60 + seconds
end
match = value.match(/([\d\. ]+)([a-zA-Z]+)/)
return time_to_seconds(value) unless match
number = match[1].to_f
unit = match[2].downcase
case unit
when 'k'
number *= 1_000
when 'm'
number *= 1_000_000
when 'b'
number *= 1_000_000_000
when 'day', 'days'
number *= 86400
when 'hour', 'hours'
number *= 3600
when 'minute', 'minutes'
number *= 60
when 'second', 'seconds'
# No multiplier needed
else
# Handle other units as needed
end
number.to_i
end
I took a more defensive approach, a lot of nil checks etc because I didn’t want the crawler to break one day because one element got renamed. It should keep running and hopefully in the future it’ll come back and update the missing values.
Videos Can Get Removed
I’ve seen videos posted one day and removed suddenly the next. So not only do you need to crawl for new videos, you also need an ongoing process to check that videos are still around. I never got around to doing this.
YouTube Hides Certain People
As I was playing around with search queries. I noticed something odd, if I searched for a specific person I would get plenty of responses from BitChute or Rumble but YouTube was mysteriously empty. Even if they were not political people, at some point they were hidden. Maybe because of time, they are not revelant anymore.
One would not expect this because there were 1000x more YouTube videos than the others. Remember, the crawlers mostly find videos by recommendations, which means YouTube is purposefully not recommending these types of videos.
This led me down the rabbit hole of finding this site dedicated to people who have been hidden from YouTube.
Conclusion
In the end I chose to shut down this project because the noise to usefulness was too high. It didn’t make sense to have crawlers running 24/7 to find a million videos and only maybe 1% are worth watching. And who would pay for this? I don’t think the average person would.
Also YouTube is massive, everything has their own viewing habits and interests. A simple keyword search is not good enough anymore.
It’s really about quality over quantity. People really just need a way to see new videos of people they enjoy watching. In my research I found plenty of open-source projects which help with this. For example:
- https://invidious.io/
- https://github.com/FreeTubeApp/FreeTube
- https://newpipe.net/
- https://github.com/amitbl/blocktube
- https://github.com/user234683/youtube-local
- https://sr.ht/~cadence/tube/
- https://www.favoree.io/
- https://codeberg.org/trizen/youtube-viewer
The Future of Search
I believe the ideal future is people build their own indexes and use community indexes to search the internet. Computers are now fast enough with enough storage space. One project solving this issue is Spyglass. And what do you know, they use Tantivy under the hood, great minds think alike.
There are also projects too such as mwmbl, and common crawl.
Going forward I will be supporting the Spyglass project. And I hope others will check it out.
Open-Sourced All Video Metadata
One last thing, you can download all the apps metadata on the Internet Archive.